Notice: This Wiki is now read only and edits are no longer possible. Please see: https://gitlab.eclipse.org/eclipsefdn/helpdesk/-/wikis/Wiki-shutdown-plan for the plan.
Configuring a Mapping (ELUG)
Contents
- 1 Configuring Common Mapping Options
- 2 Configuring Read-Only Mappings
- 3 Configuring Indirection (Lazy Loading)
- 4 Configuring XPath
- 5 Configuring a Default Null Value at the Mapping Level
- 6 Configuring Method or Direct Field Accessing at the Mapping Level
- 7 Configuring Private or Independent Relationships
- 8 Configuring Mapping Comments
- 9 Configuring a Serialized Object Converter
- 10 Configuring a Type Conversion Converter
- 11 Configuring an Object Type Converter
- 12 Configuring a Simple Type Translator
- 13 Configuring a JAXB Typesafe Enumeration Converter
- 14 Configuring Container Policy
- 15 Configuring Attribute Transformer
- 16 Configuring Field Transformer Associations
- 17 Configuring Mutable Mappings
- 18 Configuring Bidirectional Relationship
- 19 Configuring the Use of a Single Node
- 20 Configuring the Use of CDATA
This section describes how to configure EclipseLink mapping options common to two or more mapping types. This table lists the types of EclipseLink mappings that you can configure and provides a cross-reference to the type-specific chapter that lists the configurable options supported by that type.
| If you are creating... | See... |
|---|---|
The Common Mapping Options table lists the configurable options shared by two or more EclipseLink mapping types.
For more information, see the following:
Configuring Common Mapping Options
This table lists the configurable options shared by two or more EclipseLink mapping types. In addition to the configurable options described here, you must also configure the options described for the specific mapping types (see Mapping Types), as shown in the Configuring EclipseLink Mappings table.
| Option to Configure | Workbench |
Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
Configuring Read-Only Mappings
Mappings that are read-only will not be affected during insert, update, and delete operations.
Use read-only mappings when multiple attributes in an object map to the same fields in the database but only one of the mappings can write to the field.
You can also use read-only mappings with bi-directional many-to-many mappings to designate which mapping will be responsible for updating the many-to-many join table.
|
Note: The primary key mappings cannot not be read-only. |
Mappings defined for the write-lock or class indicator field must be read-only, unless the write-lock is configured not to be stored in the cache or the class indicator is part of the primary key.
Use read-only mappings only if specific mappings in a descriptor are read-only. If the entire descriptor is read-only, use the descriptor-level setting (see Configuring Read-Only Descriptors).
This table summarizes which mappings support this option.
| Mapping | Using the Workbench | Using Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure Read-Only Mappings Using Workbench
To specify a mapping as read-only, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Read-Only Option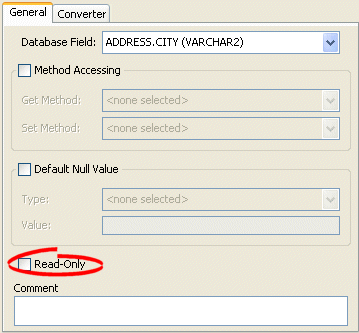

Select the Read-Only option to set the mapping to be read-only and not affected during update and delete operations.
See Also
How to Configure Read-Only Mappings Using Java
Use the following DatabaseMapping methods to configure the read access of a mapping:
- readOnly–configures mapping read access to read-only;
- readWrite–configures mapping read access to read and write (default).
This example shows how to use these methods with a class that has a read-only attribute named phones.
Configuring Read Only Mappings in Java
// Map the phones attribute
phonesMapping.setAttributeName("phones");
// Specify read-only
phonesMapping.readOnly();
Configuring Indirection (Lazy Loading)
If indirection is not enabled, when EclipseLink retrieves a persistent object, it retrieves all of the dependent objects to which it refers. When you enable indirection (lazy loading) for an attribute mapped with a relationship mapping, EclipseLink uses an indirection object as a placeholder for the referenced object: EclipseLink defers reading the dependent object until you access that specific attribute. This can result in a significant performance improvement, especially if the application is interested only in the contents of the retrieved object rather than the objects to which it refers.
We strongly recommend using indirection for all relationship mappings. Not only does this allow you to optimize data source access, but it also allows EclipseLink to optimize the unit of work processing, cache access, and concurrency.
This table summarizes which mappings support this option.
| Mapping | Value Holder Indirection | Transparent Indirect Container Indirection |
Proxy Indirection |
How to Configure Indirection Using Workbench |
How to Configure Indirection Using Java |
|---|---|---|---|---|---|
| |
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
| |
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
| |
|
|
|
| |
|
|
|
|
|
| |
|
|
|
|
|
| |
| |
|
|
|
| |
|
|
|
|
|
|
In general, we recommend that you use value holder indirection for one-to-one mappings and transparent indirect container indirection for collection mappings. Enable indirection for transformation mappings if the execution of the transformation is a resource-intensive task (such as accessing a database, in a relational project).
When using indirection with EJB, the version of EJB and application server you use affects how indirection is configured and what types of indirection are applicable.
When using indirection with an object that your application serializes, you must consider the effect of any untriggered indirection objects at deserialization time.
For JPA entities or POJO classes that you configure for weaving, EclipseLink weaves value holder indirection for one-to-one mappings. If you want EclipseLink to weave change tracking and your application includes collection mappings (one-to-many or many-to-many), then you must configure all collection mappings to use transparent indirect container indirection only (you may not configure your collection mappings to use eager loading nor value holder indirection).
For more information, see the following:
- Indirection (Lazy Loading)
- Value Holder Indirection
- Transparent Indirect Container Indirection
- Indirection, Serialization, and Detachment
- Using Weaving
- Using EclipseLink JPA Weaving
How to Configure Indirection Using Workbench
To complete the indirection options on a mapping's General tab use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Indirection Options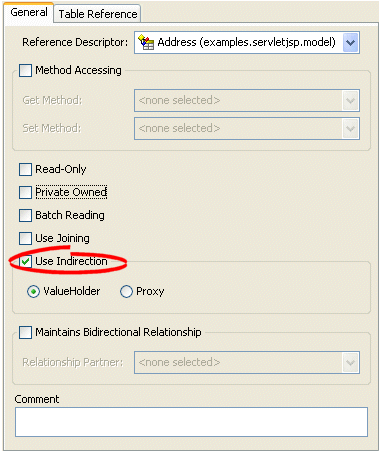
- Select the Use Indirection option and indicate the type of indirection to use.

Use the following information to complete the Indirection fields on the tab:
| Field | Description |
|---|---|
| Use Indirection | Specify if this mapping uses indirection. |
| :ValueHolder |
Specify that the mapping uses Value Holder indirection. See Value Holder Indirection for more information. |
| :Proxy |
Specify that the mapping uses Proxy indirection. See Proxy Indirection for more information. |
See Also
How to Configure Indirection Using Java
When creating mappings through the Java API, all foreign reference mappings default to using value-holder indirection and all transformation mappings default to not using indirection.
To disable indirection use ForeignReferenceMapping method dontUseIndirection.
To enable value holder indirection, use ForeignReferenceMapping method useBasicIndirection.
To enable transparent container indirection, use one of the following CollectionMapping methods:
- useTransparentCollection
- useTransparentList
- useTransparentMap
- useTransparentSet
To enable proxy indirection, use ObjectReferenceMapping method useProxyIndirection.
This section provides additional information on the following:
- Configuring ValueHolder Indirection
- Configuring ValueHolder Indirection With Method Accessing
- Configuring IndirectContainer Indirection
- Configuring Proxy Indirection
Configuring Value Holder Indirection
Instances of org.eclipse.persistence.mappings.ForeignReferenceMapping and org.eclipse.persistence.mappings.foundation.AbstractTransformationMapping provide the useBasicIndirection method to configure a mapping to an attribute that you code with an org.eclipse.persistence.indirection.ValueHolderInterface between it and the real object.
If the attribute is of a Collection type (such as a Vector), then you can either use an IndirectContainer (see Configuring IndirectContainer Indirection) or define the ValueHolder in the constructor as follows:
addresses = new ValueHolder(new Vector());
This example illustrates the Employee class using ValueHolder indirection. The class definition conceals the use of ValueHolder within the existing getter and setter methods.
Class Using ValueHolder Indirection
public class Employee {
protected ValueHolderInterface address;
// Initialize ValueHolders in constructor
public Employee() {
address = new ValueHolder();
}
public Address getAddress() {
return (Address) this.addressHolder.getValue();
}
public void setAddress(Address address) {
this.addressHolder.setValue(address);
}
}
This example shows how to configure a one-to-one mapping to the address attribute.
Mapping Using ValueHolder Indirection
OneToOneMapping mapping = new OneToOneMapping();
mapping.useBasicIndirection();
mapping.setReferenceClass(Employee.class);
mapping.setAttributeName("address");
The application uses Employee methods getAddress and setAddress to access the Address object. Because basic indirection is enabled, EclipseLink expects the persistent fields to be of type ValueHolderInterface.
Configuring Value Holder Indirection with Method Accessing
If you are using ValueHolder indirection with method accessing (see Configuring Method or Direct Field Accessing at the Mapping Level), in addition to changing your attributes types in your Java code to ValueHolderInterface, you must also provide EclipseLink with two pairs of getter and setter methods:
- getter and setter of the indirection object that are registered with the mapping and used only by EclipseLink. They include a get method that returns an instance that conforms to ValueHolderInterface, and a set method that accepts one argument that conforms to the same interface;
- getter and setter of the actual attribute value used by the application.
This example illustrates the Employee class using ValueHolder indirection with method access. The class definition is modified so that the address attribute of Employee is a ValueHolderInterface instead of an Address, and appropriate getter and setter methods are supplied.
Class Using ValueHolder Indirection with Method Accessing
public class Employee {
protected ValueHolderInterface address;
// Initialize ValueHolders in constructor
public Employee() {
address = new ValueHolder();
}
// getter and setter registered with the mapping and used only by EclipseLink
public ValueHolderInterface getAddressHolder() {
return address;
}
public void setAddressHolder(ValueHolderInterface holder) {
address = holder;
}
// getter and setter methods used by the application to access the attribute
public Address getAddress() {
return (Address) address.getValue();
}
public void setAddress(Address theAddress) {
address.setValue(theAddress);
}
}
This example shows how to configure a one-to-one mapping to the address attribute.
Mapping Using ValueHolder Indirection with Method Accessing
OneToOneMapping mapping = new OneToOneMapping();
mapping.useBasicIndirection();
mapping.setReferenceClass(Employee.class);
mapping.setAttributeName("address");
mapping.setGetMethodName("getAddressHolder");
mapping.setSetMethodName("setAddressHolder");
The application uses Employee methods getAddress and setAddress to access the Address object. Because basic indirection is enabled, EclipseLink uses Employee methods getAddressHolder and setAddressHolder methods when performing persistence operations on instances of Employee.
Configuring Value Holder Indirection with JPA
When using indirection with JPA, if your application serializes any indirection-enabled (lazily loaded) entity (see Indirection, Serialization, and Detachment), then, to preserve untriggered indirection objects on deserialization, configure your client to use EclipseLink agent, as follows:
- Include the following JAR files (from <ECLIPSELINK_HOME>\jlib) in your client classpath:
- eclipselink.jar
- <your-application-persistence>.jar
- Add the following argument to the Java command line you use to start your client: -javaagent:eclipselink-agent.jar
You can also use static weaving. This will provide you with better error messages and will resolve merging issues.
|
Note: The use of static weaving will not affect serialization as it functions without static weaving enabled. |
Configuring IndirectContainer Indirection
Instances of org.eclipse.persistence.mappings.ForeignReferenceMapping and org.eclipse.persistence.mappings.foundation.AbstractTransformationMapping provide the useContainerIndirection method to configure a mapping to an attribute that you code with an org.eclipse.persistence.indirection.IndirectContainer between it and the real object.
Using an IndirectContainer, a java.util.Collection class can act as an EclipseLink indirection object: the Collection will only read its contents from the database when necessary (typically, when a Collection accessor is invoked). Without an IndirectContainer, all members of the Collection must be retrieved when the Collection attribute is accessed.
The following example illustrates the Employee class using IndirectContainer indirection with method access. Note that the fact of using indirection is transparent.
Class Using IndirectContainer Indirection
public class Employee {
protected List addresses;
public Employee() {
this.addresses = new ArrayList();
}
public List getAddresses() {
return this.addresses;
}
public void setAddresses(List addresses) {
this.addresses = addresses;
}
}
The following example shows how to configure a one-to-one mapping to the addresses attribute.
Mapping Using IndirectContainer Indirection
OneToOneMapping mapping = new OneToOneMapping();
mapping.useBasicIndirection();
mapping.setReferenceClass(Employee.class);
mapping.setAttributeName("addresses");
mapping.setGetMethodName("getAddresses");
mapping.setSetMethodName("setAddresses");
Configuring Proxy Indirection
This example illustrates an Employee to Address one-to-one relationship.
Classes Using Proxy Indirection
public interface Employee {
public String getName();
public Address getAddress();
public void setName(String value);
public void setAddress(Address value);
. . .
}
public class EmployeeImpl implements Employee {
public String name;
public Address address;
. . .
public Address getAddress() {
return this.address;
}
public void setAddress(Address value) {
this.address = value;
}
}
public interface Address {
public String getStreet();
public void setStreet(String value);
. . .
}
public class AddressImpl implements Address {
public String street;
. . .
}
In the preceding example, both the EmployeeImpl and the AddressImpl classes implement public interfaces (Employee and Address respectively). Therefore, because the AddressImpl class is the target of the one-to-one relationship, it is the only class that must implement an interface. However, if the EmployeeImpl is ever to be the target of another one-to-one relationship using transparent indirection, it must also implement an interface, as the following example shows:
Employee emp = (Employee) session.readObject(Employee.class);
System.out.println(emp.toString());
System.out.println(emp.getAddress().toString());
// Would print:
[Employee] John Smith
{ IndirectProxy: not instantiated }
String street = emp.getAddress().getStreet();
// Triggers database read to get Address information
System.out.println(emp.toString());
System.out.println(emp.getAddress().toString());
// Would print:
[Employee] John Smith
{ [Address] 123 Main St. }
Using proxy indirection does not change how you instantiate your own domain objects for an insert operation. You still use the following code:
Employee emp = new EmployeeImpl("John Smith");
Address add = new AddressImpl("123 Main St.");
emp.setAddress(add);
The following example illustrates an Employee to Address one-to-one relationship mapping.
Mapping Using Proxy Indirection
OneToOneMapping mapping = new OneToOneMapping();
mapping.useProxyIndirection();
mapping.setReferenceClass(Employee.class);
mapping.setAttributeName("address");
mapping.setGetMethodName("getAddress");
mapping.setSetMethodName("setAddress");
Configuring XPath
EclipseLink uses XPath statements to map the attributes of a Java object to locations in an XML document. When you create an XML mapping or EIS mapping using XML records, you can specify the XPath based on any of the following:
- Name
- Position
- Path and name
This table summarizes which mappings support this option.
| Mapping | Using the Workbench |
How to Use Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
1 When used with XML records only.
2 Supports the self XPath (".") so that the EclipseLink runtime performs all read and write operations in the parent's element and not an element nested within it (see Mappings and the jaxb:class Customization).
Before you can select an XPath for a mapping, you must associate the descriptor with a schema context (see Configuring Schema Context for an EIS Descriptoror Configuring Schema Context for an XML Descriptor).
For more information, see Mappings and XPath.
How to Configure XPath Using Workbench
Use this table to select the XPath for an XMl mapping or EIS mapping using XML records:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- If necessary, click the General tab. The General tab appears.
General Tab, XPath Options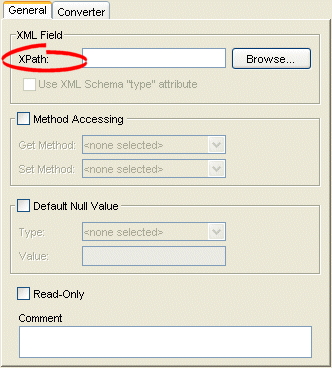
XPath Options for Composite Object Mappings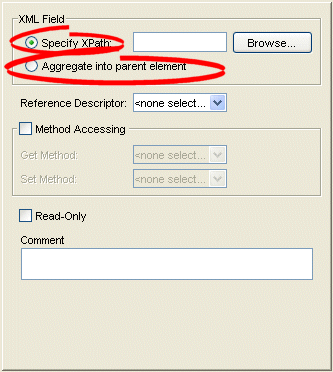
- Click Browse and select the XPath to map to this attribute (see Choosing the XPath).


For an EIS composite object mapping using XML records or an XML composite object mapping, you can choose one of the following:
- Specify XPath: select the XPath to map to this attribute (see Choosing the XPath).
- Aggregate into parent element: select the self XPath (".") (see Self XPath) so that the EclipseLink runtime performs all read and write operations in the parent's element, and not an element nested within it (see Mappings and the jaxb:class Customization).
Choosing the XPath
From the Choose XPath dialog box, select the XPath and click OK. Workbench builds the complete XPath name.
Choose XPath Dialog Box

Configuring a Default Null Value at the Mapping Level
A default null value is the Java Object type and value that EclipseLink uses instead of null when EclipseLink reads a null value from a data source.
When you configure a default null value at the mapping level, EclipseLink uses it to translate in the following two directions:
- When EclipseLink reads null from the data source, it converts this null to the specified type and value.
- When EclipseLink writes or queries to the data source, it converts the specified type and value back to null.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
|
Note: A default null value must be an Object. To specify a primitive value (such as int), you must use the corresponding Object wrapper (such as Integer). |
You can also use EclipseLink to set a default null value for all mappings used in a session (see Configuring a Default Null Value at the Login Level).
How to Configure a Default Null Value at the Mapping Level Using Workbench
To configure a default null value for a mapping, use this procedure.
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Default Null Value Options
General Tab, Default Null Value Options - Complete the Default Null Value fields on the tab.
Use the following information to complete the Default Null Value fields on the tab:
| Field | Description |
|---|---|
| Default Null Value | Specify if this mapping contains a default value in the event that the data source is null. If selected, you must enter both the Type and Value of the default. |
|
Select the Java type of the default value. |
|
Enter the default value. |
How to Configure a Default Null Value at the Mapping Level Using Java
To configure a mapping null value using Java API, use the AbstractDirectMapping method setNullValue.
For example:
// Defaults a null salary to 0 salaryMapping.setNullValue(new Integer(0));
Configuring Method or Direct Field Accessing at the Mapping Level
By default, EclipseLink uses direct access to access public attributes. Alternatively, you can use getter and setter methods to access object attributes when writing the attributes of the object to the database, or reading the attributes of the object from the database. This is known as method access.
Using private, protected or package variable or method access requires you to enable the Java reflect security setting. This is enabled by default in most application servers (see How to Set Security Permissions), but may need to be enabled explicitly in certain JVM configurations. If necessary, use the java.policy file to grant ReflectPermission to the entire application or the application's code base. For example:
grant{
permission java.lang.reflect.ReflectPermission;
};
We recommend using direct access whenever possible to improve performance and avoid executing any application-specific behavior while building objects.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
|
For information on configuring method accessing at the project level, see Configuring Method or Direct Field Access at the Project Level.
If you enable change tracking on a property (for example, you decorate method getPhone with @ChangeTracking) and you access the field (phone) directly, note that EclipseLink does not detect the change. For more information, see Using Method and Direct Field Access.
How to Configure Method or Direct Field Accessing Using Workbench
To complete the field access method for a mapping, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Method Accessing Options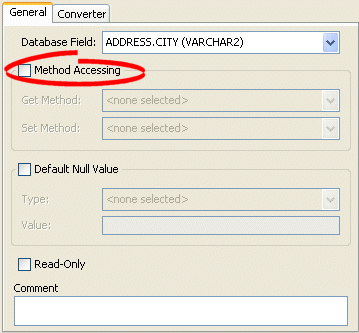
- Complete the Method Accessing fields on the tab.

Use the following information to complete the Method Accessing fields on this tab:
| Field | Description |
|---|---|
| Method Accessing | Specify if this mapping uses specific accessor methods instead directly accessing public attributes. By default, this option is not selected (that is, the mapping uses direct access). |
|
Select a specific get method. |
|
Select a specific set method. |
To change the default access type used by all new mappings, use the Defaults tab on the project Editor window. See Configuring Method or Direct Field Access at the Project Level for more information.
See Also
- Configuring Method or Direct Field Accessing at the Mapping Level
- Using Method and Direct Field Access
How to Configure Method or Direct Field Accessing Using Java
Use the following DatabaseMapping methods to configure the user-defined getters and setters that EclipseLink will use to access the mapped attribute:
For mappings not supported in Workbench, use the setGetMethodName and setSetMethodName methods to access the attribute through user-defined methods, rather than directly, as follows:
- setGetMethodName–set the String name of the user-defined method to get the mapped attribute;
- setSetMethodName–set the String name of the user-defined method to set the mapped attribute.
This example shows how to use these methods with a class that has an attribute phones and accessor methods getPhones and setPhones in an object-relational data type mapping.
Configuring Access Method in Java
// Map the phones attribute
phonesMapping.setAttributeName("phones");
// Specify access method
phonesMapping.setGetMethodName("getPhones");
phonesMapping.setSetMethodName("setPhones");
Configuring Private or Independent Relationships
In EclipseLink, object relationships can be either private or independent:
- In a private relationship, the target object is a private component of the source object. The target object cannot exist without the source and is accessible only through the source object. Destroying the source object will also destroy the target object.
- In an independent relationship, the source and target objects are public ones that exist independently. Destroying one object does not necessarily imply the destruction of the other.
|
Tip: EclipseLink automatically manages private relationships. Whenever an object is written to the database, any private objects it owns are also written to the database. When an object is removed from the database, any private objects it owns are also removed. Be aware of this when creating new systems, since it may affect both the behavior and the performance of your application. |
This table summarizes which mappings support this option.
| Mapping | Implicitly Private | Private or Independent | Using Workbench |
Using Java |
|---|---|---|---|---|
| |
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
| |
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
| |
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
| |
|
|
| |
|
|
|
|
| |
|
|
|
|
| |
|
|
|
|
|
How to Configure Private or Independent Relationships Using Workbench
To create a privately owned mapping, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Private Owned option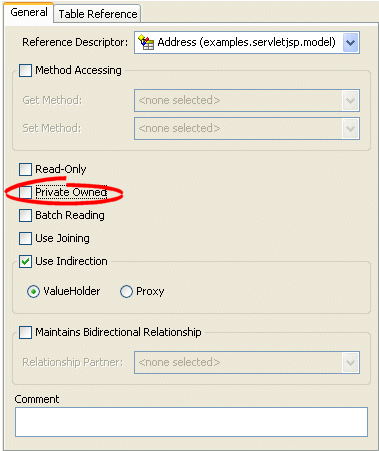
- To create private ownership, select the Private Owned option.

How to Configure Private or Independent Relationships Using Java
For mappings not supported in the Workbench, use the independentRelationship (default), privateOwnedRelationship, and setIsPrivateOwned methods.
This exampple shows how to use these methods with a class that has a privately owned attribute, phones, in a mapping.
Configuring Access Method in Java
// Map the phones attribute
phonesMapping.setAttributeName("phones");
// Specify as privately owned
phonesMapping.privateOwnedRelationship();
Configuring Mapping Comments
You can define a free-form textual comment for each mapping. You can use these comments however you wish: for example, to record important project implementation details such as the purpose or importance of a mapping.
Comments are stored in the Workbench project, in the EclipseLink deployment XML file. There is no Java API for this feature.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
How to Use Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
|
How to Configure Mapping Comments Using Workbench
To add a comment for a mapping, use this procedure.
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Comment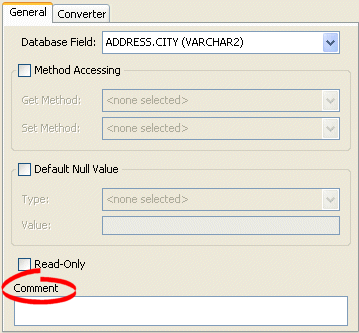
- Enter a comment that describes this mapping.

Configuring a Serialized Object Converter
A serialized object converter can be used to store an arbitrary object or set of objects into a data source binary large object (BLOB) field. It uses the Java serializer so the target must be serializable.
For more information about the serialized object converter, see Serialized Object Converter.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
| |
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure a Serialized Object Converter Using Workbench
To create an serialized object direct mapping, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the Converter tab. The Converter tab appears.
Converter Tab, Serialized Object Converter Option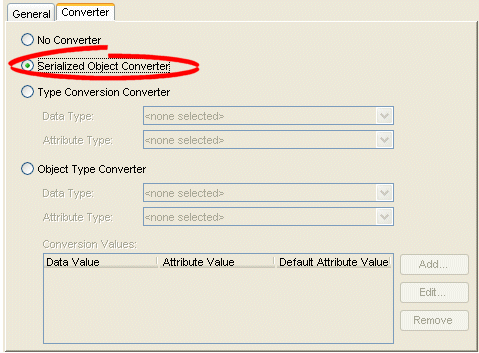
- To specify a serialized object converter, select the Serialized Object Converter option.

How to Configure a Serialized Object Converter Using Java
You can set an org.eclipse.persistence.converters.SerializedObjectConverter on any instance of org.eclipse.persistence.mappings.foundation.AbstractCompositeDirectCollectionMapping or its subclasses using the AbstractCompositeDirectCollectionMapping method setValueConverter, as this example shows.
Configuring a SerializedObjectConverter in Java
// Create SerializedObjectConverter instance
SerializedObjectConverter serializedObjectConvter = new SerializedObjectConverter();
// Set SerializedObjectConverter on ArrayMapping
ArrayMapping arrayMapping = new ArrayMapping();
arrayMapping.setValueConverter(serializedObjectConvter);
arrayMapping.setAttributeName("responsibilities");
arrayMapping.setStructureName("Responsibilities_t");
arrayMapping.setFieldName("RESPONSIBILITIES");
orDescriptor.addMapping(arrayMapping);
You can also set a SerializedObjectConverter on any instance of org.eclipse.persistence.mappings.foundation.AbstractDirectMapping or its subclasses using the AbstractDirectMapping method setConverter.
Configuring a Type Conversion Converter
A type conversion converter is used to explicitly map a data source type to a Java type.
For more information about the type conversion converter, see Type Conversion Converter.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
| |
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure a Type Conversion Converter Using Workbench
To create an type conversion direct mapping, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the Converter tab. The Converter tab appears.
- Select the Type Conversion Converter option.
Converter Tab, Type Conversion Converter Option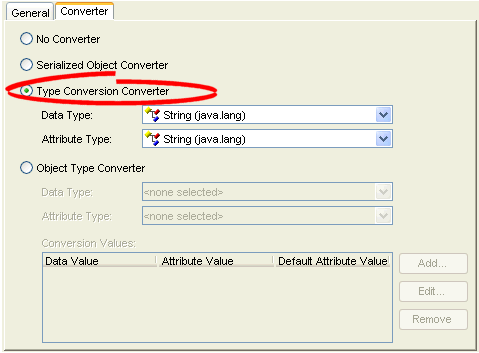
- Complete Type Conversion Converter fields on the Converter tab.

Use the following information to complete the Type Conversion Converter fields on the Converter tab:
| Field | Description |
|---|---|
| Data Type | Select the Java type of the data in the data source. |
| Attribute Type | Select the Java type of the attribute in the Java class. |
How to Configure a Type Conversion Converter Using Java
You can set an org.eclipse.persistence.converters.TypeConversionConverter on any instance of org.eclipse.persistence.mappings.foundation.AbstractCompositeDirectCollectionMapping or its subclasses using the AbstractCompositeDirectCollectionMapping method setValueConverter, as this exmaple shows.
Configuring a TypeConversionConverter
// Create TypeConversionConverter instance
TypeConversionConverter typeConversionConverter = new TypeConversionConverter();
typeConversionConverter.setDataClass(java.util.Calendar.class);
typeConversionConverter.setObjectClass(java.sql.Date.class);
// Set TypeConversionConverter on ArrayMapping
ArrayMapping arrayMapping = new ArrayMapping();
arrayMapping.setValueConverter(typeConversionConverter);
arrayMapping.setAttributeName("date");
arrayMapping.setStructureName("Date_t");
arrayMapping.setFieldName("DATE");
orDescriptor.addMapping(arrayMapping);
You can also set a TypeConversionConverter on any instance of org.eclipse.persistence.mappings.foundation.AbstractDirectMapping or its subclasses using the AbstractDirectMapping method setConverter.
Configure the TypeConversionConverter instance using the following API:
- setDataClass(java.lang.Class dataClass)–to specify the data type class.
- setObjectClass(java.lang.Class objectClass)–to specify the object type class.
Configuring an Object Type Converter
An object type converter is used to match a fixed number of data source data values to Java object values. It can be used when the values in the data source and in Java differ.
For more information about the object type converter, see Object Type Converter.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
|
|
| |
| |
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure an Object Type Converter Using Workbench
To add an object type converter to a direct mapping, use this procedure:
- Select the mapping in the Navigator. Its properties appear in the Editor.
- Click the Converter tab. The Converter tab appears.
Converter Tab, Object Type Converter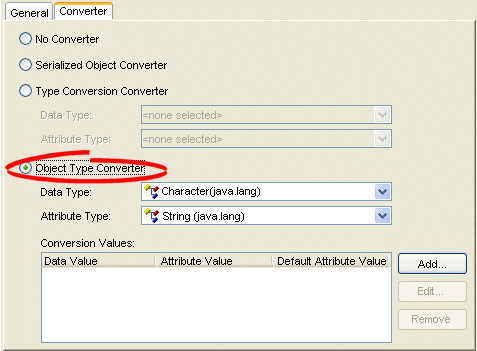
- Select the Object Type Converter option on the tab.

Use the following fields on the mapping's Converter tab to specify the object type converter options:
| Field | Description |
|---|---|
| Data Type | Select the Java type of the data in the data source. |
| Attribute Type | Select the Java type of the attribute in the Java class. |
| Conversion Values |
Click Add to add a new conversion value. Click Edit to modify an existing conversion value. Click Remove to delete an existing conversion value. Use to specify the selected value as the default value. If EclipseLink retrieves a value from the database that is not mapped as a valid Conversion Value, the default value will be used. |
|
Specify the value of the attribute in the data source. |
|
Specify the value of the attribute in the Java class |
|
Specify whether or not to use the selected value as the default value. If EclipseLink retrieves a value from the database that is not mapped as a valid Conversion Value, the default value will be used. |
How to Configure an Object Type Converter Using Java
You can set an org.eclipse.persistence.converters.ObjectTypeConverter on any instance of org.eclipse.persistence.mappings.foundation.AbstractCompositeDirectCollectionMapping using AbstractCompositeDirectCollectionMapping method setValueConverter.
You can also set an ObjectTypeConverter on any instance of org.eclipse.persistence.mappings.foundation.AbstractDirectMapping or its subclasses using the AbstractDirectMapping method setConverter, as the following example shows.
Configuring an ObjectTypeConverter in Java
// Create ObjectTypeConverter instance
ObjectTypeConverter objectTypeConvter = new ObjectTypeConverter();
objectTypeConverter.addConversionValue("F", "Female");
// Set ObjectTypeConverter on DirectToFieldMapping
DirectToFieldMapping genderMapping = new DirectToFieldMapping();
genderMapping.setConverter(objectTypeConverter);
genderMapping.setFieldName("F");
genderMapping.setAttributeName("Female");
descriptor.addMapping(genderMapping);
Configure the ObjectTypeConverter instance using the following API:
- addConversionValue(java.lang.Object fieldValue, java.lang.Object attributeValue)–to associate data-type values to object-type values.
- addToAttributeOnlyConversionValue(java.lang.Object fieldValue, java.lang.Object attributeValue)–to add one-way conversion values.
- setDefaultAttributeValue(java.lang.Object defaultAttributeValue)–to set the default value.
Configuring a Simple Type Translator
The simple type translator allows you to automatically translate an XML element value to an appropriate Java type based on the element's <type> attribute, as defined in your XML schema. You can use a simple type translator only when the mapping's XPath goes to an element. You cannot use a simple type translator if the mapping's XPath goes to an attribute.
For more information, see Simple Type Translator.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure a Simple Type Translator Using Workbench
Use this table to qualify elements from the XML schema
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Use XML Schema "type" Attribute Option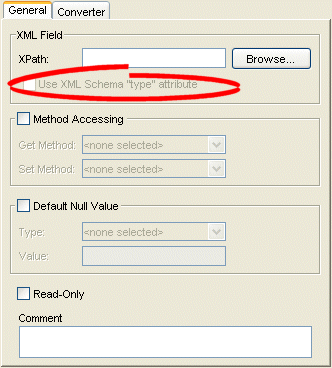
- Select the Field Uses XML Schema "type" attribute field to qualify elements from the XML schema.

How to Configure a Simple Type Translator Using Java
To create an XML mapping with a simple type translator with Java code in your IDE, you need the following elements:
- EISDirectMapping or EISCompositeDirectCollectionMapping or XMLDirectMapping or XMLCompositeDirectCollectionMapping
- instance of Converter
- instance of TypedElementField
This example shows how to implement your own simple type translator with an XMLDirectMapping to override the built-in conversion for writing XML so that EclipseLink writes a Byte array (ClassConstants.ABYTE) as a Base64 (XMLConstants.BASE64_BINARY) encoded string.
Creating a Type Translation XML Mapping
XMLDirectMapping mapping = new XMLDirectMapping();
mapping.setConverter(new SerializedObjectConverter());
TypedElementField field = new TypedElementField("element");
field.getSimpleTypeTranslator().addJavaConversion(
ClassConstants.ABYTE,
new QName(XMLConstants.SCHEMA_URL, XMLConstants.BASE64_BINARY));
mapping.setField(field);
Configuring a JAXB Typesafe Enumeration Converter
The JAXB typesafe enumeration converter allows you to automatically translate an XML element value to an appropriate typesafe enumeration value as defined in your XML schema.
For more information, see Mappings and JAXB Typesafe Enumerations.
This table summarizes which mappings support this option.
| Mapping | How to Use Workbench | Using Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
1 When used with XML records only.
The Workbench does not support the JAXBTypesafeEnumConverter directly: to configure a mapping with this converter, you must use Java to create an amendment method (see Using Java).
If you create a project and object model using the EclipseLink JAXB compiler (see Creating an XML Project from an XML Schema), the compiler will create the type safe enumeration class and a class with descriptor amendment methods and register the required amendment methods automatically (see Typesafe Enumeration Converter Amendment Method DescriptorAfterLoads Class).
How to Configure a JAXB Typesafe Enumeration Converter Using Java
To configure a mapping with a JAXBTypesafeEnumConverter in Java, use a descriptor amendment method (see Configuring Amendment Methods). This example illustrates an amendment method that configures an XMLDirectMapping with a JAXBTypesafeEnumConverter. In this example, attribute _Val is mapped to a JAXB typesafe enumeration corresponding to typesafe enumeration class MyTypesafeEnum.
Creating a JAXB Typesafe Enumeration XML Mapping
public class DescriptorAfterLoads {
public static void amendRootImplDescriptor(ClassDescriptor descriptor) {
DatabaseMapping _ValMapping = descriptor.getMappingForAttributeName("_Val");
JAXBTypesafeEnumConverter _ValConverter = new JAXBTypesafeEnumConverter();
ValConverter.setEnumClassName("MyTypesafeEnum");
((XMLDirectMapping) _ValMapping).setConverter(_ValConverter);
}
}
Configuring Container Policy
Collection mapping container policy specifies the concrete class EclipseLink should use when reading target objects from the database.
Collection mappings can use any concrete class that implements the java.util.List, java.util.Set, java.util.Collection, or java.util.Map interface. You can map object attributes declared as List, Set, Collection, Map, or any subinterface of these interfaces, or as a class that implements one of these interfaces.
By default, the EclipseLink runtime uses the following concrete classes from the org.eclipse.persistence.indirection package for each of these container types:
- List–IndirectList or Vector
- Set–IndirectSet or HashSet
- Collection–IndirectList or Vector
- Map–IndirectMap or HashSet
Alternatively, you can specify in the mapping the concrete container class to be used. When EclipseLink reads objects from the database that contain an attribute mapped with a collection mapping, the attribute is set with an instance of the concrete class specified. For example, EclipseLink does not sort in memory. If you want to sort in memory, override the default Set type (IndirectList) with java.util.TreeSet as the concrete collection type. By default, a collection mapping's container class is java.util.Vector.
|
Note: If you are using Workbench and you override the default Collection class with a custom Collection class of your own, you must put your custom Collection class on the Workbench classpath (see Configuring the Workbench Environment). |
This table summarizes which mappings support this option.
| Mapping | List | Set | Collection | Map | Using Workbench |
Using Java |
|---|---|---|---|---|---|---|
| |
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
| |
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
| |
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
| |
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
| |
|
|
|
|
|
|
|
How to Configure Container Policy Using Workbench
To specify a mapping's container policy, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
- Click the Advanced button. The Advanced Container Options appear on the General tab.
General Tab, Advanced Container Options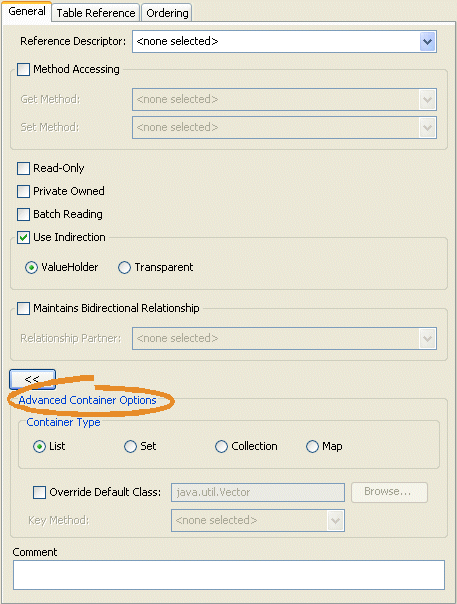
- Complete Advanced Container Options on the tab.

Use the following Advanced Container Options fields on the General tab to specify the container options:
| Field 1 | Description |
|---|---|
| Container Type |
Specify the type of Collection class to use:
|
| Override Default Class | Specify to use a custom class as the mapping's container policy. Click Browse to select a different class. The container class must implement (directly or indirectly) the java.util.Collection interface. |
| Key Method | If you configure Container Type as Map, use this option to specify the name of the zero argument method whose result, when called on the target object, is used as the key in the Hashtable or Map. This method must return an object that is a valid key in the Hashtable or Map. |
1 Not all mappings support all options. For more information, see the Mapping Support for Container Policy table.
How to Configure Container Policy Using Java
Classes that implement the org.eclipse.persistence.mappings.ContainerMapping interface provide the following methods to set the container policy:
- useCollectionClass(java.lang.Class concreteClass)–Configure the mapping to use an instance of the specified java.util.Collection container class to hold the target objects.
- useMapClass(java.lang.Class concreteClass, java.lang.String methodName)–Configure the mapping to use an instance of the specified java.util.Map container class to hold the target objects. The key used to index a value in the Map is the value returned by a call to the specified zero-argument method. The method must be implemented by the class (or a superclass) of any value to be inserted into the Map.
Classes that extend org.eclipse.persistence.mappings.CollectionMapping (which implements the ContainerMapping interface) also provide the following methods to set the container policy:
- useSortedSetClass(java.lang.Class concreteClass, java.util.Comparator comparator)–Configure the mapping to use an instance of the specified java.util.SortedSet container class. Specify the Comparator to use to sort the target objects.
The following example shows how to configure a DirectCollectionMapping to use a java.util.ArrayList container class.
Direct Collection Mapping
// Create a new mapping and register it with the source descriptor
DirectCollectionMapping phonesMapping = new DirectCollectionMapping();
phonesMapping.setAttributeName("phones");
phonesMapping.setGetMethodName("getPhones");
phonesMapping.setSetMethodName("setPhones");
phonesMapping.setReferenceTableName("PHONES_TB");
phonesMapping.setDirectFieldName("PHONES");
phonesMapping.useCollectionClass(ArrayList.class); // set container policy
descriptor.addMapping(phonesMapping);
Configuring Attribute Transformer
A transformation mapping is made up of an attribute transformer for field-to-attribute transformation at read (unmarshall) time and one or more field transformers for attribute-to-field transformation at write (marshall) time (see Configuring Field Transformer Associations).
This section describes how to configure the attribute transformer that a transformation mapping uses to perform the field-to-attribute transformation at read (unmarshal) time.
You can do this using either a method or class-based transformer.
A method-based transformer must map to a method in the domain object.
A class-based transformer allows you to place the transformation code in another class, making this approach non-intrusive: that is, your domain object does not need to implement an EclipseLink interface or provide a special transformation method
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
| |
| |
|
|
| |
| |
| |
|
|
|
How to Configure Attribute Transformer Using Workbench
To specify a mapping's attribute transformer, use this procedure:
- Select the transformation mapping in the Navigator. Its properties appear in the Editor.
Transformation Mapping, Attribute Transformer Field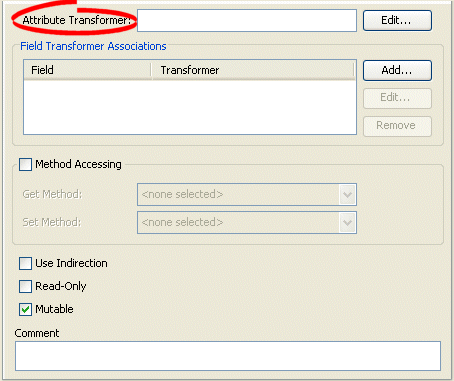
- Click Edit. The Specify Transformer dialog box appears.
Specify Transformer Dialog Box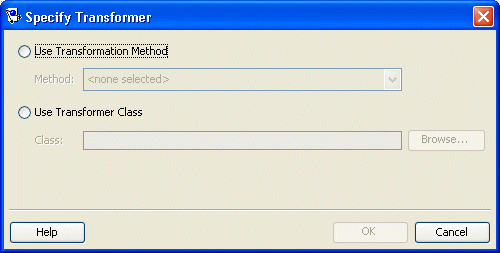
- Complete each field on the Specify Transformer dialog box and click OK.


Use the following information to enter data in each field of the dialog box and click OK:
| Field | Description |
|---|---|
| Use Transformation Method | Select a specific method to control the transformation. A method based transformer must map to a method in the domain object. |
| Use Transformer Class | Select a specific class to control the transformation. The class must be available on the Workbench application classpath. |
How to Configure Attribute Transformer Using Java
You can configure a method-based attribute transformer using AbstractTransformationMapping method setAttributeTransformation, passing in the name of the domain object method to use.
You can configure a class-based attribute transformer using AbstractTransformationMapping method setAttributeTransformer, passing in an instance of org.eclipse.persistence.mappings.Transfomers.AttributeTransformer.
A convenient way to create an AttributeTransformer is to extend AttributeTransformerAdapter.
Configuring Field Transformer Associations
A transformation mapping is made up of an attribute transformer for field-to-attribute transformation at read (unmarshall) time (see Configuring Attribute Transformer) and one or more field transformers for attribute-to-field transformation at write (marshall) time.
This section describes how to configure the field transformers that a transformation mapping uses to perform the object attribute-to-field transformation at write (marshal) time.
You can do this using either a method or class-based transformer.
A method-based transformer must map to a method in the domain object.
A class-based transformer allows you to place the transformation code in another class, making this approach non-intrusive: that is, your domain object does not need to implement an EclipseLink interface or provide a special transformation method.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
| |
| |
|
|
| |
| |
| |
|
|
|
How to Configure Field Transformer Associations Using Workbench
Use this procedure to complete the Object->Field Method fields:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
Transformation Mapping, Field Transformer Associations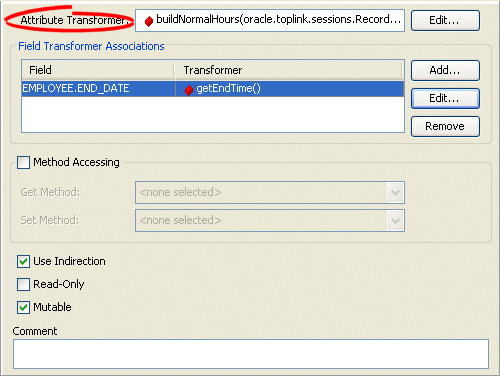
- Click Add to add the necessary Field Transformer Associations for the mapping.

To add a new association, click Add. Continue with Specifying Field-to-Transformer Associations.
To change an existing association, click Edit. Continue with Specifying Field-to-Transformer Associations.
To delete an existing association, select the field transformation association and click Delete.
Specifying Field-to-Transformer Associations
To specify the actual transformation method or class used for the field of a transformation mapping, use this procedure.
- From the Transformation Mapping, Field Transformer Associations, click Add or Edit. The Specify Field-Transformer Association dialog box appears.
Specify Field-Transformer Association Dialog Box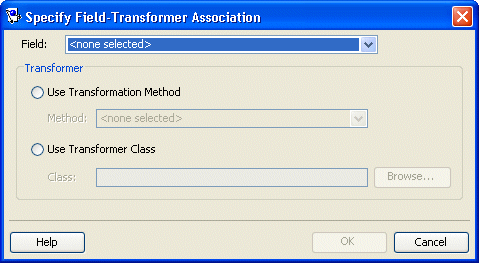
- Complete each field on the dialog box.

Use the following information to complete each field on the dialog box:
| Field | Description |
|---|---|
| Field | Select the database field (from the descriptor's associated table) for this transformation. |
| Transformer | Select one of the following methods to control the transformation: |
|
Select a specific method to control the transformation. A method based transformer must map to a method in the domain object. |
|
Select a specific class to control the transformation. The class must be available on Workbench application classpath. |
How to Configure Field Transformer Associations Using Java
You can specify a specific transformation method on your domain object or an instance of org.eclipse.persistence.mappings.Transfomers.FieldTransformer (you can also extend the FieldTransformerAdapter). Using a FieldTransformer is non-intrusive: that is, your domain object does not need to implement an EclipseLink interface or provide a special transformation method.
You can configure a method-based field transformer using AbstractTransformationMapping method addFieldTransformation, passing in the name of the database field and the name of the domain object method to use.
You can configure a class-based field transformer using AbstractTransformationMapping method addFieldTransformer, passing in the name of the database field and an instance of org.eclipse.persistence.mappings.Transfomers.FieldTransformer.
A convenient way to create a FieldTransformer is to extend FieldTransformerAdapter.
Configuring Mutable Mappings
Direct mappings typically map simple, nonmutable values such as String or Integer. Transformation mappings can potentially map complex mutable object values, such as mapping several database field values to an instance of a Java class.
If a transformation mapping maps a mutable value, EclipseLink must clone and compare the value in a unit of work (see Configuring Copy Policy).
By default, EclipseLink assumes that all transformation mappings are mutable. If the mapping maps a simple immutable value, you can improve the unit of work performance by configuring the IsMutable option to false.
By default, EclipseLink also assumes that all direct mappings are mutable unless a serialized converter is used. These mappings can also set the IsMutable option. You should set it if you want to modify Date or Calendar fields.
This table summarizes which mappings support this option.
For more information, see Mutability.
| Mapping | Using Workbench |
How to Use Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
|
How to Configure Mutable Mappings Using Workbench
Use this table to complete the Object->Field Method fields:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
Transformation Mapping, Mutable Option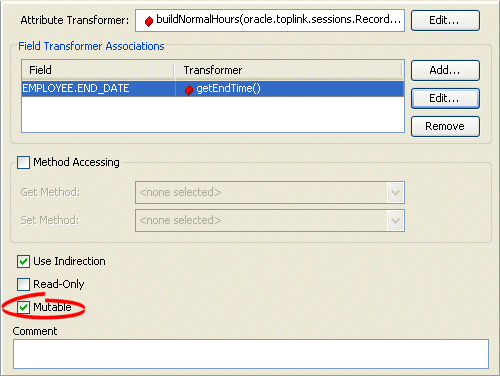
- By default, the IsMutable option is selected in all transformation mappings. If the mapping maps to a simple atomic value, unselect this option.

How to Configure Mutable Mappings Using Java
You can specify whether or not a mapping is mutable using AbstractTransformationMapping method setIsMutable for transformation mappings, and AbstractDirectMapping method isMutable for direct mappings.
Configuring Bidirectional Relationship
EclipseLink can automatically manage the bidirectional relationship: if one side of the relationship is set or modified, EclipseLink will automatically set the other side. To enable this functionality, use the value holder indirection (see Value Holder Indirection) for one-to-one mappings, and transparent collections (see Transparent Indirect Container Indirection)–for one-to-many and many-to-many mappings.
|
Note: We do not recommend using this EclipseLink feature: if the object model is used outside the persistence context it must be responsible for managing the bidirectional relationship. Instead, your application should maintain the bidirectional relationship in its getter and setter methods. |
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
|
How to Configure Bidirectional Relationship Using Workbench
To maintain a bidirectional relationship for a mapping, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General tab, Maintains Bidirectional Relationship option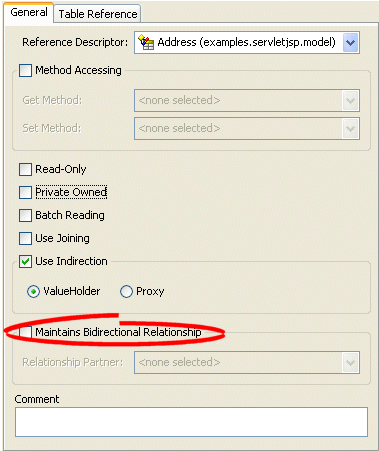
- Complete the Bidirectional Relationship fields.

Use this table to enter data in the following fields on the tab:
| Field | Description |
|---|---|
| Maintains Bidirectional Relationship | Specify if EclipseLink should maintain the bidirectional link for this relational mapping. |
| Relationship Partner | Select the relationship partner (from the list of mapped attributes of the Reference Descriptor) for this bidirectional relationship. |
How to Configure Bidirectional Relationship Using Java
If a mapping has a bidirectional relationship in which the two classes in the relationship reference each other with one-to-one mappings, then set up the foreign key information as follows:
- One mapping must call the setForeignKeyFieldName method.
- The other must call the setTargetForeignKeyFieldName method.
You can also set up composite foreign key information by calling the addForeignKeyFieldName and addTargetForeignKeyFieldName methods. Because EclipseLink enables indirection (lazy loading) by default, the attribute must be a ValueHolderInterface.
|
Note: When your application does not use a cache, enable indirection for at least one object in a bidirectional relationship. In rare cases, disabling indirection on both objects in the bidirectional relationship can lead to infinite loops. For more information, see the following: |
The following example demonstrates setting of bidirectional relationship between the Policy and Carrier classes. The foreign key is stored in the Policy’s table referencing the composite primary key of the Carrier.
Implementing a Bidirectional Mapping Between Two Classes that Reference Each Other
public class Policy {
...
// create the mapping that references the Carrier class
OneToOneMapping carrierMapping = new OneToOneMapping();
carrierMapping.setAttributeName("carrier");
carrierMapping.setReferenceClass(Carrier.class);
carrierMapping.addForeignKeyFieldName("INSURED_ID", "CARRIER_ID");
carrierMapping.addForeignKeyFieldName("INSURED_TYPE", "TYPE");
descriptor.addMapping(carrierMapping);
...
}
public class Carrier {
...
// create the mapping that references the Policy class
OneToOneMapping policyMapping = new OneToOneMapping();
policyMapping.setAttributeName("masterPolicy");
policyMapping.setReferenceClass(Policy.class);
policyMapping.addTargetForeignKeyFieldName("INSURED_ID", "CARRIER_ID");
policyMapping.addTargetForeignKeyFieldName("INSURED_TYPE", "TYPE");
descriptor.addMapping(policyMapping);
...
}
Configuring the Use of a Single Node
For the XML-based mappings that the Mapping Support for Use Single Node table summarizes, when you map a list value, you can configure whether or not the mapping unmarshalls (writes) the list to a single node, like <item>aaa bbb ccc</item>, or to multiple nodes, like the following:
<item>aaa</item> <item>bbb</item> <item>ccc</item>
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
1 When used with XML records only.
How to Configure the Use of a Single Node Using Workbench
o configure a mapping to use a single node, use this procedure.
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Use Single Node Option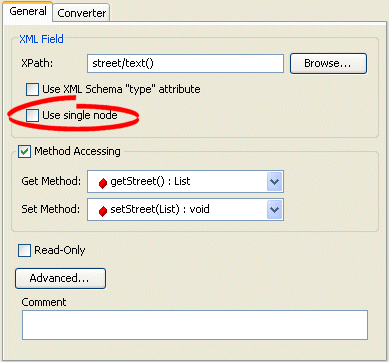
- Complete the Use single node field on the tab.

{kind=link}
- To configure the mapping to unmarshall (write) a list value to a single node (like <item>aaa bbb ccc</item>), click Use single node.
- By default, the mapping unmarshalls a list value to separate nodes.
How to Configure the Use of a Single Node Using Java
Use AbstractCompositeDirectCollectionMapping method setUsesSingleNode to configure the mapping to write a list value to a single node by passing in a value of true. To configure the mapping to write a list value to multiple nodes, pass in a value of false.
For any mapping that takes an XMLField, use XMLField method setUsesSingleNode to configure the mapping to write a list value to a single node by passing in a value of true. To configure the mapping to write a list value to multiple nodes, pass in a value of false. This example shows how to use this method with an XMLDirectMapping:
Using XMLField Method setUsesSingleNode
XMLDirectMapping tasksMapping = new XMLDirectMapping();
tasksMapping.setAttributeName("tasks");
XMLField myField = new XMLField("tasks/text()"); // pass in the XPath
myField.setUsesSingleNode(true);
tasksMapping.setField(myField);
Configuring the Use of CDATA
For the XML-based mappings that the Mapping Support for Default Null Values table summarizes, when you create a mapping, you can configure whether or not the mapping's text is wrapped in a <![CDATA[...]]> statement.
This table summarizes which mappings support this option.
| Mapping | Using Workbench |
Using Java |
|---|---|---|
| |
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure the Use of CDATA Using Java
Use the isCDATA() method on an XMLDirectMapping or XMLCompositeDirectCollectionMapping to specify if the mapping's text is wrapped in a <![CDATA[...]]> statement. The following example shows the results of using this method:
Using CDATA
When isCDATA = false on the name mapping, EclipseLink writes the text as a regular text node:
<employee> <name>Jane Doe</name> </employee>
When isCDATA = true on the name mapping, EclipseLink wraps the text in a <![CDATA[...]]> statement:
<employee>
<name>
<![CDATA[Jane Doe]]>
</name>
</employee>