Notice: This Wiki is now read only and edits are no longer possible. Please see: https://gitlab.eclipse.org/eclipsefdn/helpdesk/-/wikis/Wiki-shutdown-plan for the plan.
Configuring a Relational Mapping (ELUG)
Contents
For information on how to create EclipseLink mappings, see Creating a Mapping.
This table lists the types of relational mappings that you can configure and provides a cross-reference to the type-specific chapter that lists the configurable options supported by that type.
| If you are creating... | See... |
|---|---|
For more information, see the following:
Configuring Common Relational Mapping Options
This table lists the configurable options shared by two or more relational mapping types.
| Option to Configure | Workbench | Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
Configuring a Database Field
You can associate an object attribute with a database field.
This table summarizes which relational mappings support this option.
| Mapping | Using the Workbench | How to Use Java |
|---|---|---|
|
|
| |
|
|
|
When choosing the database field, you must consider Java and database field type compatibility.
EclipseLink supports the following Java types:
- java.lang: Boolean, Float, Integer, String, Double, Long, Short, Byte, Byte[ ], Character, Character[ ]; all the primitives associated with these classes
- java.math: BigInteger, BigDecimal
- java.sql: Date, Time, Timestamp
- java.util: Date, Calendar
While executing reads, the mappings in the Relational Mapping Support for Reference Descriptor table perform the simple one-way data conversions that the Type Conversions Provided by Direct-to-Field Mappings table describes. For two-way or more complex conversions, You must use converters).
The mappings in this table also allow you to specify a null value. This may be required if primitive types are used in the object, and the database field allows null values. For more information, see Configuring a Default Null Value at the Mapping Level.
Type Conversions Provided by Direct-to-Field Mappings
| Java type | Database type |
|---|---|
|
Integer, Float, Double, Byte, Short, BigDecimal, BigInteger, int, float, double, byte, short |
NUMBER, NUMERIC, DECIMAL, FLOAT, DOUBLE, INT, SMALLINT, BIT, BOOLEAN |
|
Boolean, boolean |
BOOLEAN, BIT, SMALLINT, NUMBER, NUMERIC, DECIMAL, FLOAT, DOUBLE, INT |
|
String |
VARCHAR, CHAR, VARCHAR2, CLOB, TEXT, LONG, LONG VARCHAR, MEMOThe following types apply only to Oracle9: NVARCHAR2, NCLOB, NCHAR |
|
byte[ ] |
BLOB, LONG RAW, IMAGE, RAW, VARBINARY, BINARY, LONG VARBINARY |
|
Time |
TIME |
|
java.sql.Date |
DATE |
|
Timestamp, java.util.Date, Calendar |
TIMESTAMP |
Support for oracle.sql.TimeStamp
EclipseLink provides additional support for mapping Java date and time data types to Oracle Database DATE, TIMESTAMP, and TIMESTAMPTZ data types when you use the Oracle JDBC driver with Oracle9i Database Server or later and the Oracle9Platform in EclipseLink.
In a direct-to-field mapping, you are not required to specify the database type of the field value; EclipseLink determines the appropriate data type conversion.
This table lists the supported direct-to-field mapping combinations.
Supported Oracle Database Date and Time Direct-to-Field Mappings
| Java Type | Database Type | Description |
|---|---|---|
|
java.sql.Time |
TIMESTAMP |
Full bidirectional support. |
|
TIMESTAMPTZ |
Full bidirectional support. | |
|
DATE |
Full bidirectional support. | |
|
java.sql.Date |
TIMESTAMP |
Full bidirectional support. |
|
TIMESTAMPTZ |
Full bidirectional support. | |
|
DATE |
Full bidirectional support. | |
|
java.sql.Timestamp |
TIMESTAMP |
Full bidirectional support. |
|
TIMESTAMPTZ |
Full bidirectional support. | |
|
DATE |
Nanoseconds are not stored in the database. | |
|
java.util.Date |
TIMESTAMP |
Full bidirectional support. |
|
TIMESTAMPTZ |
Full bidirectional support. | |
|
DATE |
Milliseconds are not stored in the database. | |
|
java.util.Calendar |
TIMESTAMP |
Native SQL or binding gives Calendar timezone. Note: The TIMESTAMP database value has no timezone – the Calendar object provides the local timezone by default. If the database is not in this timezone, you must obtain the database timezone by some other means and update the Calendarobject accordingly. For this reason, TIMESTAMPTZ may be a better choice. |
|
TIMESTAMPTZ |
Native SQL or binding stores timezone; standard SQL is based on the local timezone. | |
|
DATE |
Neither timezone nor milliseconds are stored in the database. |
Note that some of these mappings result in a loss of precision: avoid these combinations if you require this level of precision. For example, if you create a direct-to-field mapping between a java.sql.Date attribute and a TIMESTAMPTZ database field, there is no loss of precision. However, if you create a direct-to-field mapping between a java.sql.Timestamp attribute and a DATE database field, the nanoseconds or milliseconds of the attribute are not stored in the database.
How to Configure a Database Field Using Workbench
Use this procedure to select a specific database field for a direct mapping.
- Select the direct mapping attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
Direct Mapping General Tab, Database Field Option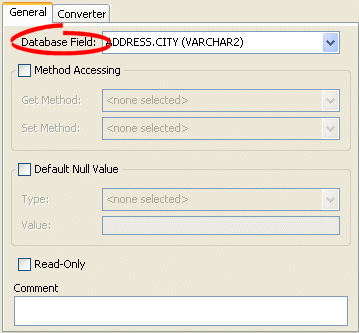
- Use the Database Field field to select a field for this direct mapping. You must have previously associated the descriptor with a database table as described in Configuring Associated Tables.

|
Note: For direct-to-field mappings of an aggregate descriptor (see Configuring a Relational Descriptor as a Class or Aggregate Type), this field is for display only and cannot be changed. |
Configuring Reference Descriptor
In relational mappings that extend org.eclipse.persistence.mappings.ForeignReferenceMapping, attributes reference other EclipseLink descriptors–not the data source. You can select any descriptor in the project.
This table summarizes which relational mappings support this option.
| Mapping | Using the Workbench | How to Use Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure a Reference Descriptor Using Workbench
To specify a reference descriptor for a relational mapping, use this procedure.
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Reference Descriptor Field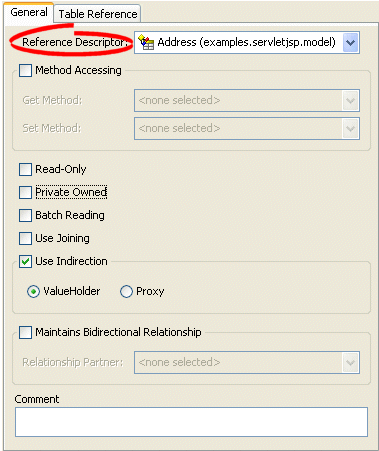
- Use the Reference Descriptor field to select the descriptor referenced by this relationship mapping.

|
Note: For aggregate mappings the Reference Descriptor must be an aggregate. See Configuring a Relational Descriptor as a Class or Aggregate Type for more information. For variable one-to-one mappings, the Reference Descriptor must be an interface. See Configuring a Relational Variable One-to-One Mapping for more information. |
You can specify a reference descriptor that is not in the current Workbench project. For example, to create a mapping to an Employee class that does not exist in the current project, do the following:
- Add the Employee class to your current project. See Working with Projects.
- Create the relationship mapping to the Employee descriptor.
- Deactivate the Employee descriptor. See Active and Inactive Descriptors.
When you generate the deployment XML for your project, the mapping to the Employee class will be included, but not the Employee class.
See Also:
Configuring Batch Reading
Batch reading can be used in most of the relational mappings. This feature should be used only if it is known that the related objects are always required with the source object.
This table summarizes which relational mappings support this option.
| Mapping | Using the Workbench | Using Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
How to Configure Batch Reading Using Workbench
To use batch reading in a relationship mapping, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Batch Reading Option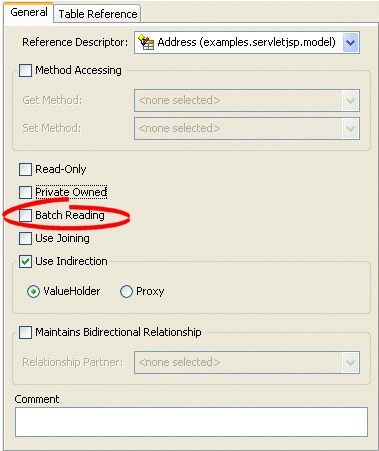
- To specify that this mapping using batch reading, select the Batch Reading option.

How to Configure Batch Reading Using Java
This example shows how to use a DescriptorCustomizer class to add batch reading to a mapping.
Query Optimization Using Batching
public void customize(ClassDescriptor descriptor) { OneToManyMapping phoneNumbersMapping = new OneToManyMapping(); phoneNumbersMapping = (OneToManyMapping)descriptor.getMappingForAttributeName("phones"); phoneNumbersMapping.useBatchReading(); }
Configuring Query Key Order
You can configure EclipseLink to maintain collections in order by query key.
This table summarizes which relational mappings support this option.
| Mapping | Using the Workbench | Using Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
|
How to Configure Query Key Order Using Workbench
To specify the order of a mapping's query keys, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the Ordering tab. The Ordering tab appears.
Ordering Tab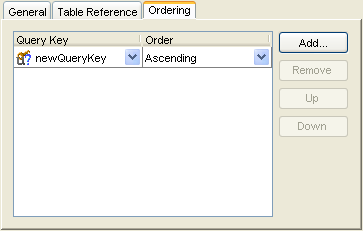
- Complete the Ordering options on the tab.

| Field | Description |
|---|---|
| Query Key |
Specify the query key to order by. Click Add to add query keys to, or Remove to remove query keys from the ordering operation. Click Up or Down to change the sort order of selected query keys. |
| Order | Specify if EclipseLink orders the selected query key in Ascending or Descending (alphabetical) order. |
How to Configure Query Key Order Using Java
This example shows how to use the DescriptorCustomizer class to add complex ordering to a mapping.
Configuring Query Key Order
public void customize(ClassDescriptor descriptor) { OneToManyMapping phoneNumbersMapping = new OneToManyMapping(); phoneNumbersMapping = (OneToManyMapping)descriptor.getMappingForAttributeName("phones"); phoneNumbersMapping.addAscendingOrdering("areaCode"); ExpressionBuilder phone = phoneNumbersMapping.getSelectionQuery().getExpressionBuilder(); phoneNumbersMapping.getSelectionQuery().addOrdering( phone.get("type").toUpperCase().ascending()); }
|
Note: You can provide the same functionality by using a descriptor amendment method (see Using the Descriptor Amendment Methods). |
Configuring Table and Field References (Foreign and Target Foreign Keys)
A foreign key is a combination of one or more database columns that reference a unique key, usually the primary key, in another table. Foreign keys can be any number of fields (similar to a primary key), all of which are treated as a unit. A foreign key and the parent key it references must have the same number and type of fields.
Mappings that extend org.eclipse.persistence.mappings.ForeignReferenceMapping use foreign keys to find information in the database so that the target object(s) can be instantiated. For example, if every Employee has an attribute address that contains an instance of Address (which has its own descriptor and table) then, the one-to-one mapping for the address attribute would specify foreign key information to find an Address for a particular Employee.
EclipseLink classifies foreign keys into two categories in mappings–foreign keys and target foreign keys:
- In a foreign key, the key is found in the table associated with the mapping's own descriptor. For example, an Employee foreign key to ADDRESS would be in the EMPLOYEE table.
- In a target foreign key, the reference is from the target object's table back to the key from the mapping's descriptor's table. For example, the ADDRESS table would have a foreign key to EMPLOYEE.
|
Caution: Make sure you fully understand the distinction between foreign key and target foreign key before defining a mapping. |
The table reference is the database table that contains the foreign key references.
This table summarizes which relational mappings support this option.
| Mapping | Using the Workbench | Using Java |
|---|---|---|
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
| |
|
|
|
Using Workbench, you can either import this table from your database or create it. If you import tables from the database (see Importing Tables from a Database), EclipseLink creates references that correspond to existing database constraints (if supported by the driver). You can also define references in EclipseLink without creating similar constraints on the database.
How to Configure Table and Field References (Foreign and Target Foreign Keys) Using Workbench
To specify a table for a mapping reference, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the Table Reference tab. The Reference tab appears.
Table Reference Tab, Table Reference Field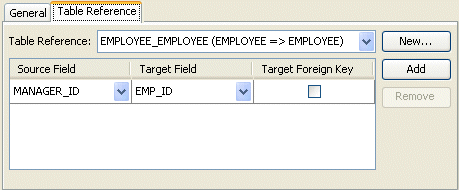
- Complete the fields on the Table Reference tab.

Use the following information to select the field references on the tab:
| Field | Description |
|---|---|
| Table Reference | Select an existing table, or click New to create a new table reference. |
| Source and Target Field |
Click Add to create new foreign key reference. To delete an existing key pair reference, select the Source and Target fields and click Remove. |
| Source Field | Select the database field from the source table for this foreign key reference. |
| Target Field | Select the database field from the target table for this foreign key reference. |
| Target Foreign Key | Specify whether or not the reference is from the target object's table back to the key from the mapping's descriptor's table. |
See Also:
How to Configure Table and Field References (Foreign and Target Foreign Keys) Using Java
Use the addTargetForeignKeyFieldName method (and pass the name of the field name of the target foreign key and the source of the primary key in the source table) to specify foreign key information.
For composite source primary keys, use the addTargetForeignKeyFieldName method for each of the fields that comprise the primary key.
This esxample shows how to use the DescriptorCustomizer class to add complex join to a mapping.
Adding Complex Join to a Mapping
public void customize(ClassDescriptor descriptor) { OneToManyMapping phoneNumbersMapping = new OneToManyMapping(); phoneNumbersMapping = (OneToManyMapping)descriptor.getMappingForAttributeName("cellPhones"); ExpressionBuilder phone = phoneNumbersMapping.getSelectionQuery().getExpressionBuilder(); phoneNumbersMapping.addTargetForeignKeyFieldName("PHONE.EMP_ID", "EMP.ID"); phoneNumbersMapping.getSelectionQuery( phone.getField("PHONE.EMP_ID").equal(phone.getParameter("EMP.ID"). and(phone.getField("PHONE.TYPE').equal("CELL"))); }
|
Note: You can provide the same functionality by using a descriptor amendment method (see Using the Descriptor Amendment Methods). |
Configuring Joining at the Mapping Level
EclipseLink supports configuring an inner or outer join at the mapping level for a ForeignReferenceMapping. When a class that owns the mapping is read, the EclipseLink runtime will always get the class and the target of the reference mapping with one database hit.
Use this feature only if the target object is always required with the source object, or when indirection (lazy loading) is not used. For more information, see Indirection (Lazy Loading).
You can also configure join reading at the query level. For more information, see Join Reading and Object-Level Read Queries.
For more information about joins, see Expressions for Joining and Complex Relationships.
How to Configure Joining at the Mapping Level Using Workbench
To use joining in a relationship mapping, use this procedure:
- Select the mapped attribute in the Navigator. Its properties appear in the Editor.
- Click the General tab. The General tab appears.
General Tab, Use Joining Option
General Tab, Use Joining Option - To use joining with this relationship, select the Use Joining option.
{kind=link}
See Also:
How to Configure Joining at the Mapping Level Using Java
This example shows how to use the DescriptorCustomizer class to add complex join at the mapping level.
Adding Join at the Mapping Level
public void customize(ClassDescriptor descriptor) { OneToManyMapping addressMapping = new OneToManyMapping(); addressMapping = (OneToManyMapping)descriptor.getMappingForAttributeName("address"); addressMapping.useJoining(); ... }
|
Note: You can provide the same functionality by using a descriptor amendment method (see Using the Descriptor Amendment Methods). |